Are problems with more (alternating) quantifiers more difficult?
An idle thought: does the “difficulty” of proving a statement increase with its quantifier complexity?
This topic sometimes arises in describing the appeal of nonstandard analysis: moving to the nonstandard setting reduces the number of quantifiers needed to, for example, define a limit from three to one. This arguably makes definitions easier to understand and statements easier to work with for students and experts alike; for instance, Terence Tao notes in an expository post that working within the nonstandard analysis universe can:
“…greatly reduc[e] epsilon management issues by automatically concealing many of the quantifiers in one’s argument.”
More generally, Hartley Rogers Jr.’s comment in Theory of Recursive Functions and Effective Computability is often quoted in the literature:
“As has been occasionally remarked, the human mind seems limited in its ability to understand and visualize beyond four or five alternations of quantifiers. Indeed, it can be argued that the inventions, subtheories, and central lemmas of various parts of mathematics are devices for assisting the mind in dealing with one or two additional alternations of quantifiers.”
That said, there are plenty of famous open problems that can be reduced to a deceptively-simple-looking statement low on the arithmetic hierarchy (see the last reference listed at the bottom of this post for examples), so there are clearly limits to the ability of the quantifier complexity of a statement to predict the difficulty that awaits its would-be prover.
For some definition of difficulty…
The Thousands of Problems for Theorem Provers (TPTP) dataset, maintained by Geoff Sutcliffe and Michael Rawson and hosted by the University of Miami, offers a way to approach in a quantitative way this question of whether quantifier complexity impacts the “difficulty” of proving a statement. This dataset offers a treasure trove of problems and summary data about each, including total quantifier count and a difficulty ranking based on the extent to which the problem can be solved by various automated theorem provers (ATPs).
Now one can reasonably argue that there is a distinction between a proof that is difficult for a human to understand and one that is difficult for a machine (automated theorem prover) to generate. And yet, should a suitable notion of “difficulty” not have to at least account for both categories? Our brains could struggle to handle a particular statement–perhaps because it has many alternating quantifiers–but if we can easily program an automated theorem prover to obtain a proof for us, is it really a difficult problem? For a given property to be judged a good measure of “difficulty” one might therefore require that automated provers be increasingly challenged as this measure of difficulty grows.
The TPTP data
We reviewed the TPTP’s data dictionary (currently retrievable here) and downloaded TPTP-v9.2.1. Within the latter, we grabbed the file labelled ProblemAndSolutionStatistics in the Documents subfolder. This file contains summary statistics about each problem, including the problem’s difficulty rating (listed under the column labelled “Rtng”), the total number of universal quantifiers (column labelled “!”) and existential quantifiers (column labelled “?”). However, we are mostly interested in the number of alternating quantifiers rather than their total counts, and we will need to compute this ourselves for the subset of problems for which it makes sense to do so.
We vibe-coded a script (posted on our github) to extract the information from ProblemAndSolutionStatistics and properly format it into a .csv file. We manually spot checked that the extracted entries matched those of the original file.
Computing quantifier alternation depths
There is a wonderful program called tptp-utils created by Alexander Steen that, among other helpful functionalities, can convert many types of TPTP problems into prenex normal form, where all quantifiers are moved to the front of a formula. Having problems in this form makes it easy to count the number of changes between quantifier types, allowing us to compute quantifier alternation depths for a large number of problems.
We vibe-coded another script to call tptp-utils on suitable problems to try to convert them to prenex normal form, compute the quantifier alternation depth of the conjecture if successful, and store the results as “conjecture_depth” in a .csv file.
Our script also tries to compute the maximum quantifier alternation depth across the full environment (conjecture plus all included axioms), referenced as “environment_depth” in the file. This captures the complexity of the logical environment the prover must reason about. A TPTP problem file typically has some directives to include axioms such as include('Axioms/SET006+0.ax'). The tool (tptp-utils --recursive normalize --prenex) first expands all of these, inlining every axiom file. The result is the full environment: all axiom formulas plus the conjecture formula is given as a single flat list of formulas. Every formula is then converted to prenex normal form.
To compute the latter we had to cap the maximum formulae number per problem to 70,000, which excluded 241 problems, because of hardware and runtime limitations. A further 3 edge-case syntax problems failed to process.
Problems in clause normal form (CNF) and the one problem in typed clause normal form (TCF) all trivially have alternation depth $0$ because formulas in these Skolemized formats have no quantifier alternation to count. We exclude these from further analysis.
Problems in typed first-order form with arithmetic (TX0) and typed first-order form with polymorphism (TF1) could not always be converted into prenex normal form by tptp-utils. We default to excluding these two collections of problems for which we have incomplete quantifier alternation depth values in the statistical analysis that follows. However, we do check whether including them would not drastically alter the results presented.
| Type | Count | With Conj. QA Depth | With Env. QA Depth |
|---|---|---|---|
| FOF | 9,259 | 9,258 * | 9,063 |
| CNF | 8,344 | 8,344 ** | 8,344 ** |
| TH0 | 3,951 | 3,950 * | 3,944 |
| TF0 | 2,113 | 2,113 *** | 2,023 |
| TH1 | 1,077 | 1,077 | 1,077 |
| TF1 | 678 | 88 | 88 |
| TX0 | 342 | 223 | 223 |
| NX0 | 196 | 196 | 196 |
| TX1 | 149 | 0 | 0 |
| DH0 | 85 | 85 | 85 |
| DH1 | 46 | 46 | 46 |
| NH0 | 23 | 22 * | 22 |
| TCF | 1 | 1 ** | 1 ** |
* One problem per category could not be processed (edge-case syntactic domain problems).
** All problems in this format are Skolemized and trivially have alternation depth 0.
*** There are fifty parametrized entries of problem SWX000_1 that lack problem files.
We merged the quantifier alternation depth data with the problem statistics csv using a small script.
Selecting appropriate test data subsets
We subset the problems to those that have meaningful alternation depth computed for all problems in their categories (excluding one-off errors for syntactic test/edge problems that could not be processed). To do so we exclude problems of the form CNF, TCF, TX0, TF1, and TX1 by default for the reasons explained in the section above.
We also need problems to have a difficulty rating, and currently DH0 and DH1 lack benchmark ratings, so we also exclude these. This leaves us with 16,198 problems from the FOF, TH0, TF0, TH1, NX0, and NH0 categories with difficulty ratings.
Of these, we are left with a test data subset of 16,195 problems that have conjecture quantifier alternation depth ratings, and one with 15,954 problems that have environment quantifier alternation depth ratings.
Selecting an appropriate statistical test
The conjecture quantifier alternation depth count, the environment quantifier alternation depth count, nor the rating values follow a normal distribution. In general the variables we will look at in this blog post are non-normally distributed, justifying the use of Spearman’s rank correlation throughout. This is not surprising given the nature of the data, and can be inferred both visually through Q-Q plots and through the skewness and kurtosis of the variables.
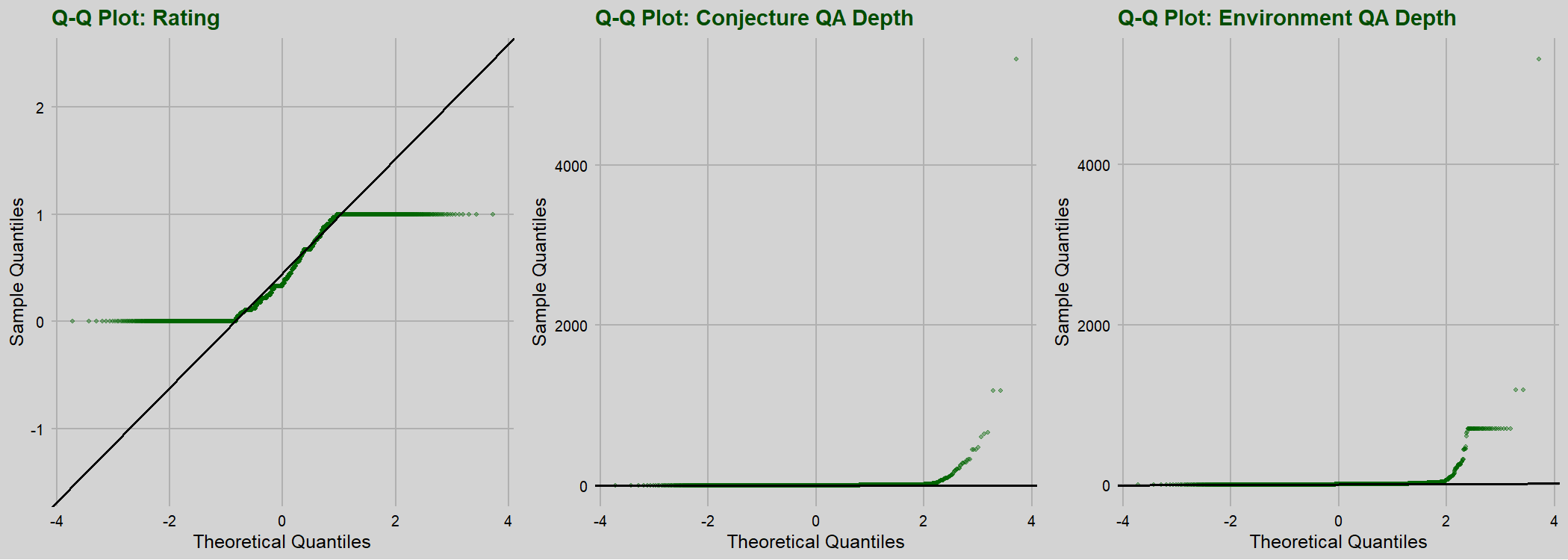
| Variable | Skewness | Excess Kurtosis |
|---|---|---|
| Rating | 0.31 | -1.42 |
| Conj. QA Depth | 59.82 | 4,257.85 |
| Env. QA Depth | 28.33 | 1,369.41 |
| Total Quantifiers | 6.01 | 44.02 |
| Universal | 6.16 | 46.66 |
| Existential | 8.45 | 96.44 |
| Connectives | 9.14 | 131.11 |
| Atoms | 6.88 | 55.29 |
| Variables | 5.91 | 42.68 |
| Symbols | 8.41 | 110.92 |
| Predicates | 15.85 | 370.20 |
| Functors | 9.04 | 123.22 |
Most of the problems (79.4%) have a conjecture quantifier alternation depth of 0, but this is far less pronounced for environment quantifier alternation depth (34.2%).
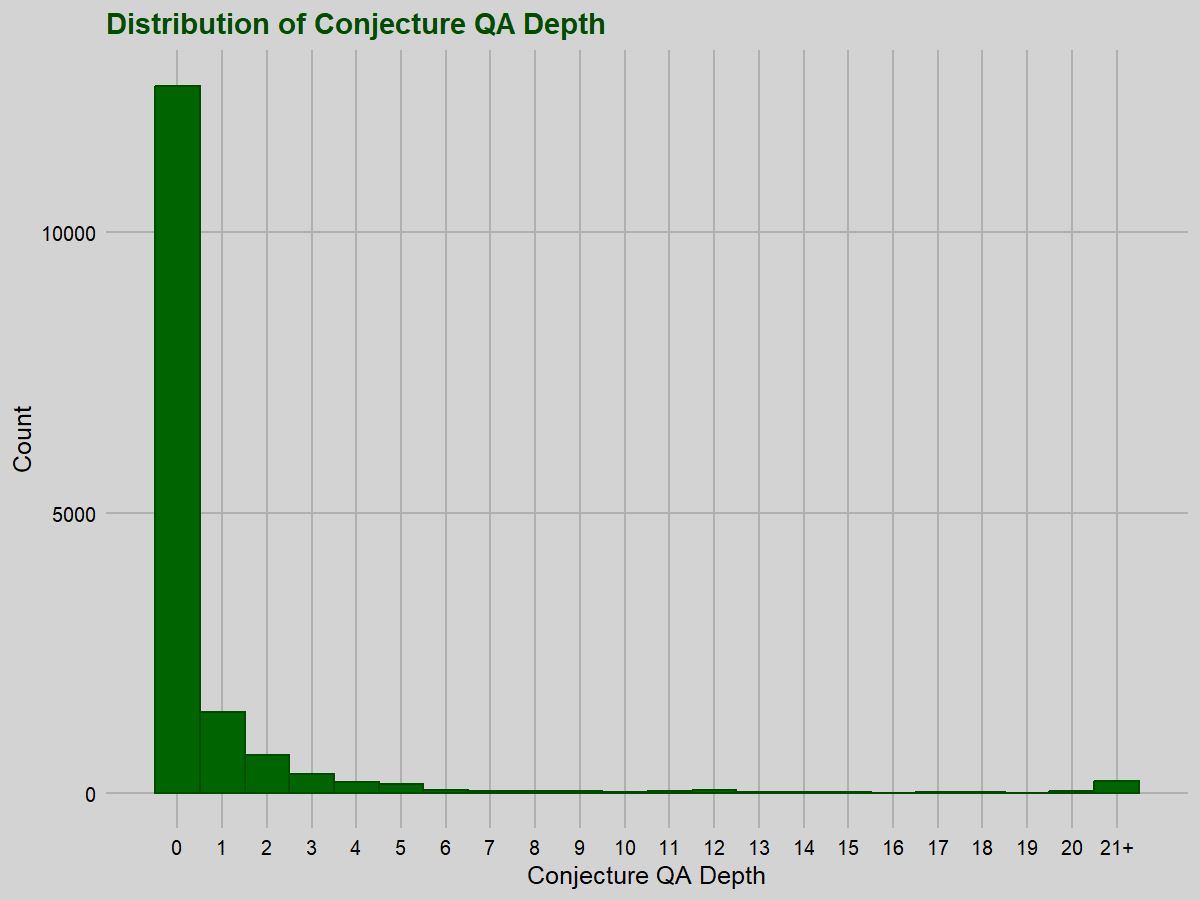
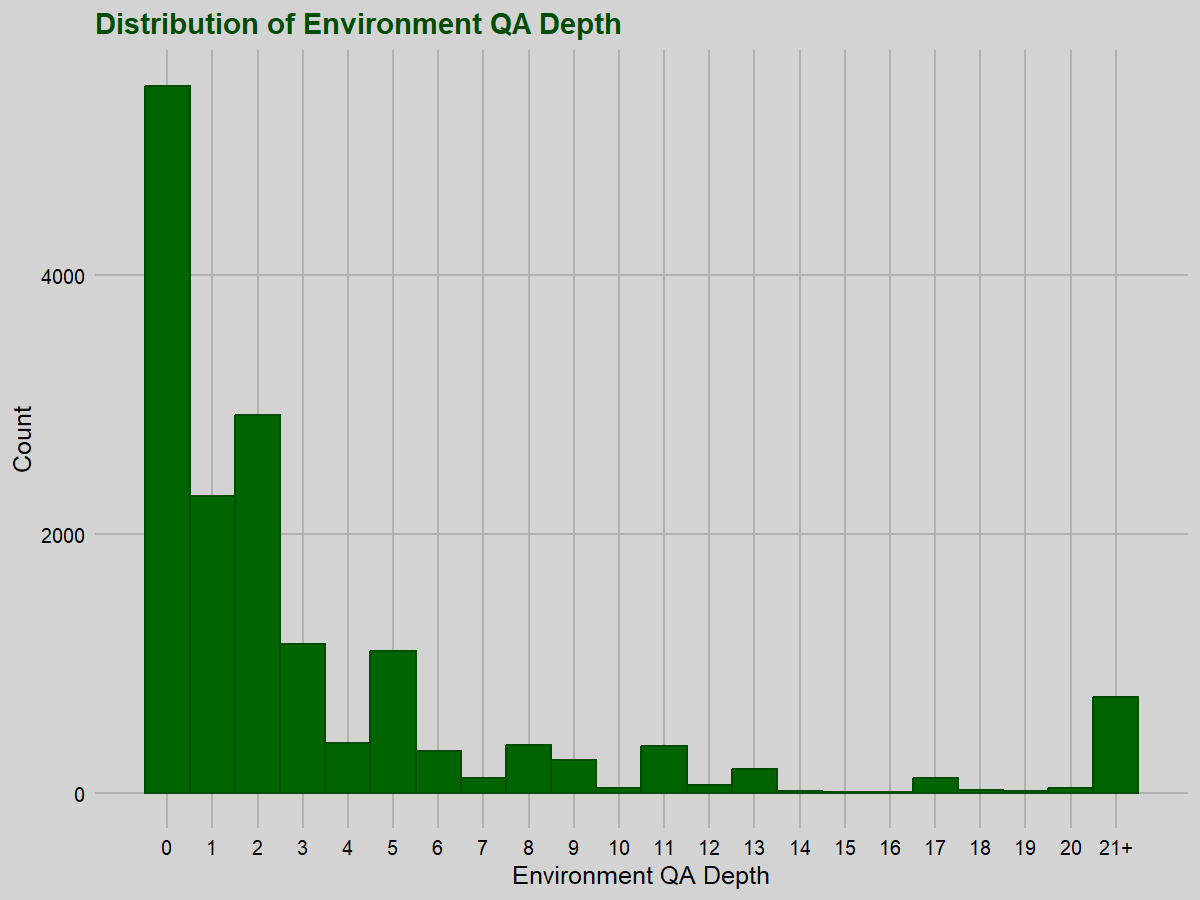
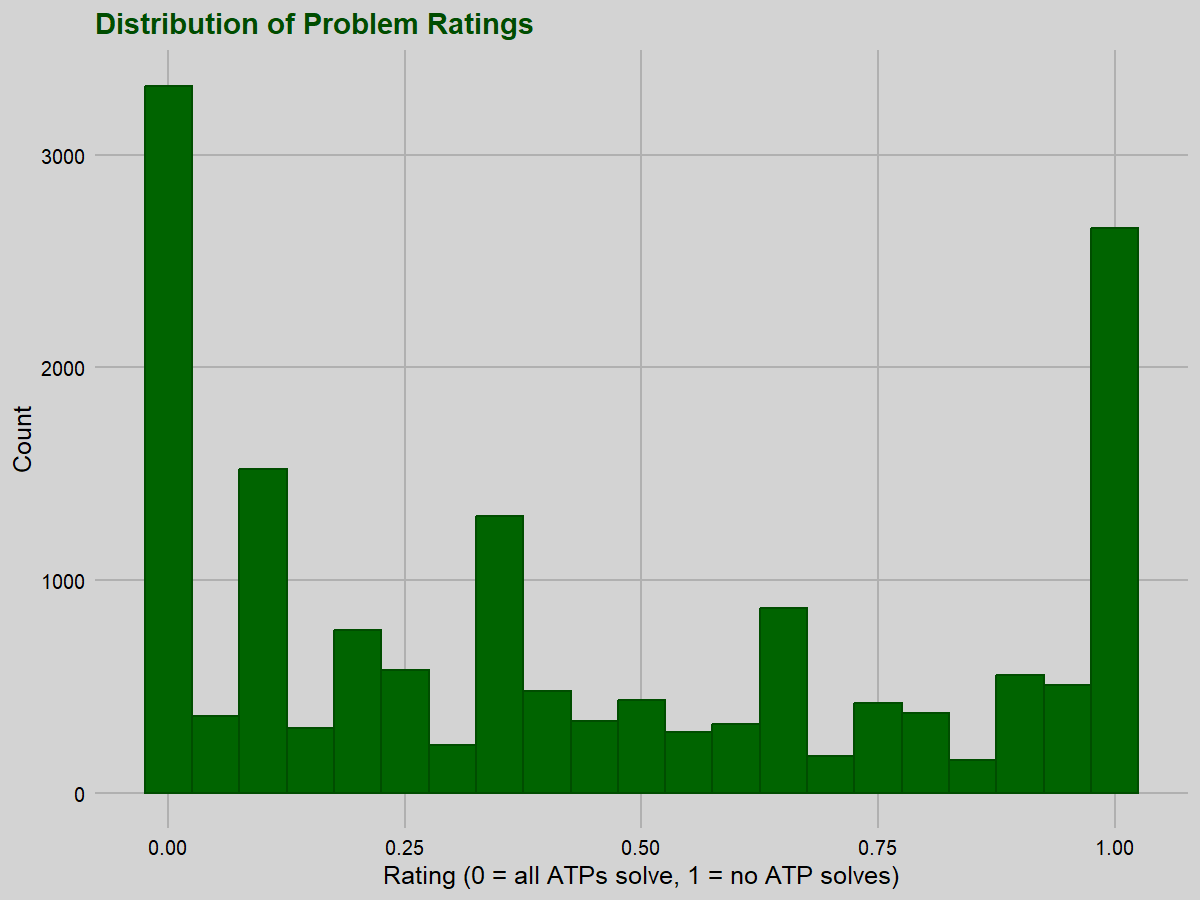
For the reader wary of multiple comparisons: yes, we do perform quite a few comparisons, but the correlations we highlight as meaningful all have p-values far below any reasonable corrected thresholds.
Conjecture QA depth versus difficulty
Conjecture quantifier alternation depth has no meaningful correlation with problem difficulty (Spearman’s rank correlation rho=-0.0128, and it is not even statistically significant with p=0.103).
This lack of meaningful correlation does not change if we:
- restrict to the 3341 problems with conjecture quantifier alternation depth of at least 1 (rho=0.0396, p=0.022), or
- include the TF1 and TX0 problems that have ratings (rho=-0.0111, p=0.156), or
- restrict to the 11240 first-order problems only (rho=-0.0355, p<0.001).
Environment QA depth versus difficulty
By contrast, the environment quantifier alternation depth is correlated with problem difficulty (rho=0.451, p<0.001).
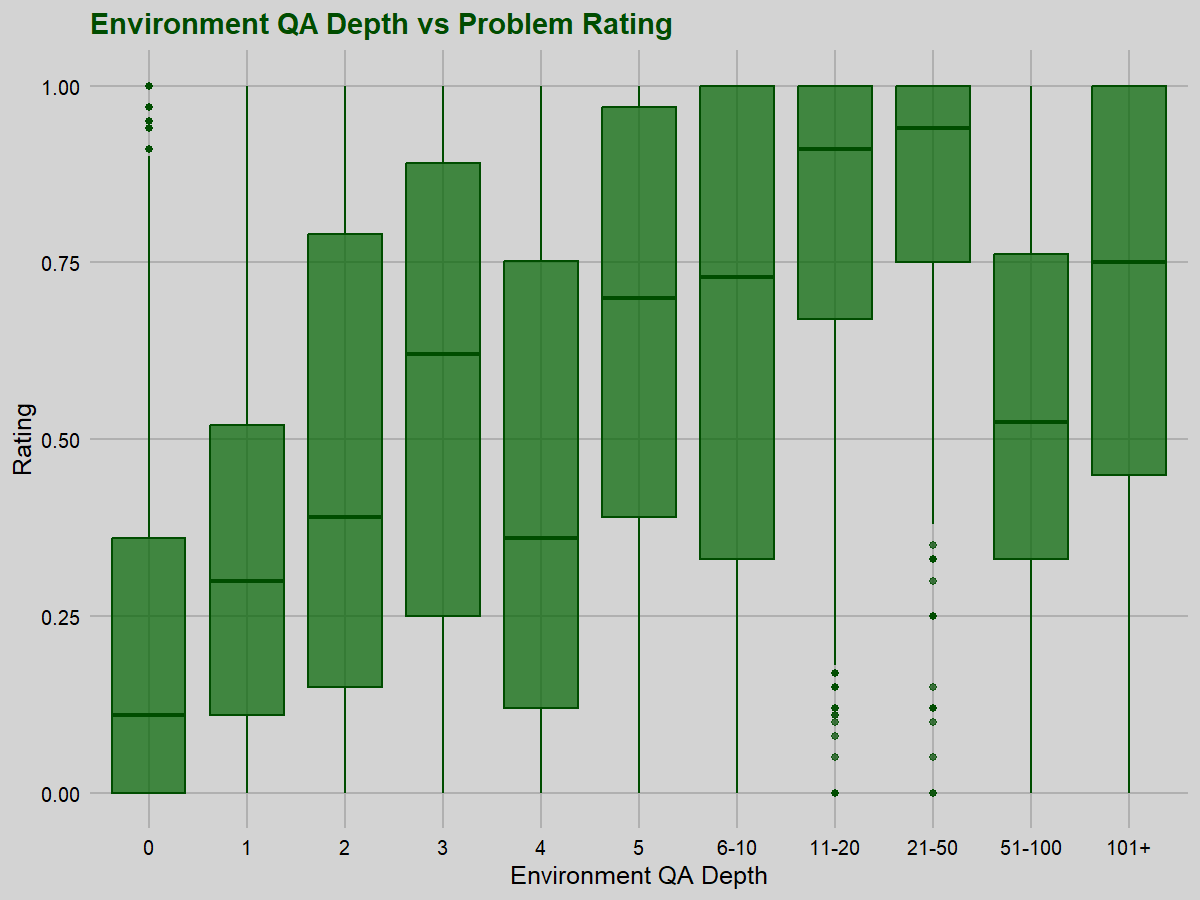
The correlation remains but notably decreases if we remove environment quantifier alternation depth 0 problems (rho=0.346, p<0.001), and if we remove both depth 0 and depth 1 problems (rho=0.286, p<0.001). There is a significant difficulty jump between having and not having some quantifier alternation depth to deal with. The jump between depth 0 and 1 is most pronounced, and we see a steady correlation erosion afterwards.
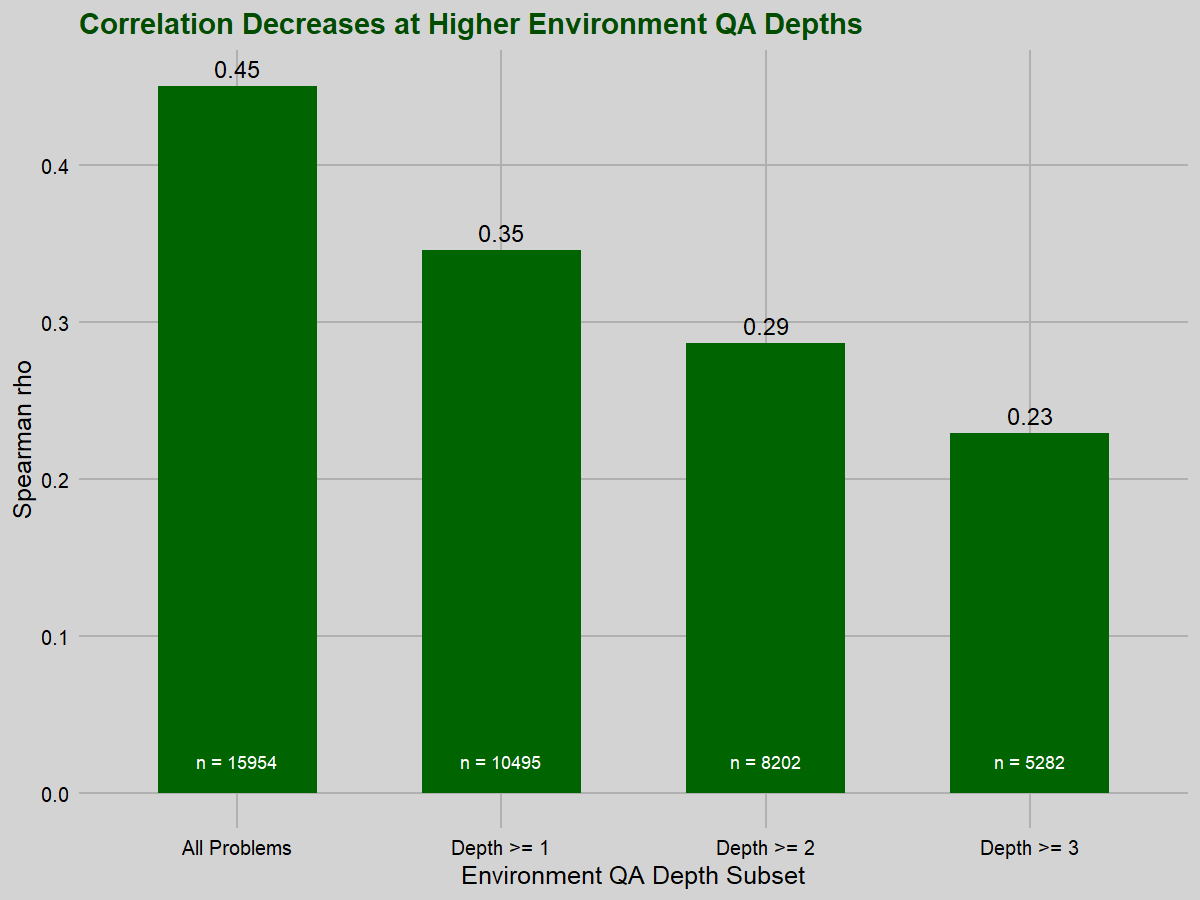
These results are robust to reasonable changes in the dataset. They do not meaningfully change if:
- we include the subset of TF1 and TX0 problems for which we were able to obtain alternation depths;
- we remove problems that have alternation depths in the top 1% of values;
- we remove all problems with the maximum difficulty rating of 1, or all problems with the minimum difficulty rating of 0, or both;
- we restrict ourselves to only first-order logic problems.
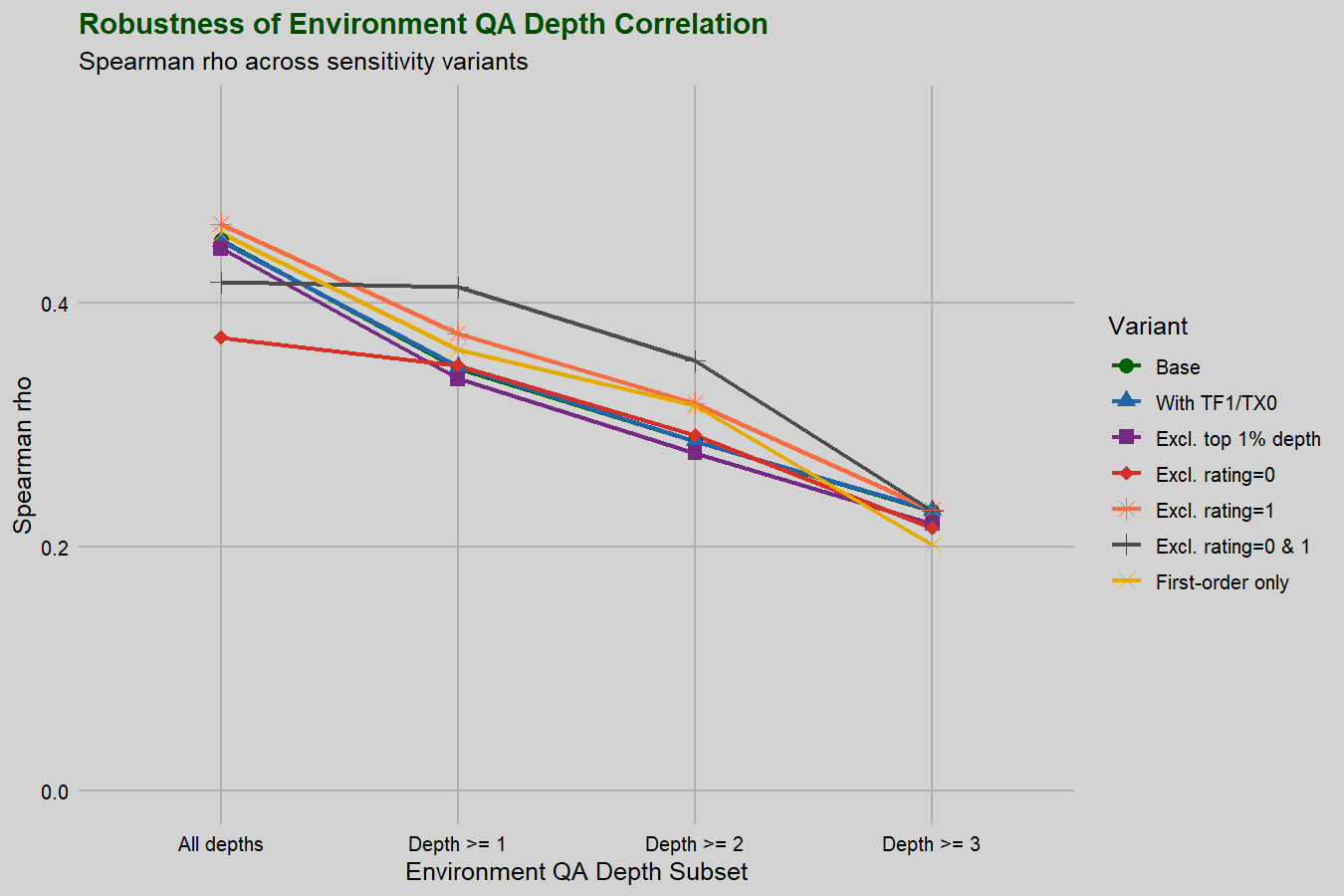
Controlling for conjecture statement impact on environment depth
When we computed the environment QA depth, we made the arbitrary decision to include the conjecture statement’s QA count: if the conjecture had a higher QA count than the axioms, we used that number. It is worth checking what happens when we remove the conjecture’s possible contribution.
In this section, we restrict ourselves to only problems with conjecture QA count of 0; as we saw above, this still leaves us with a large majority of the available problems.
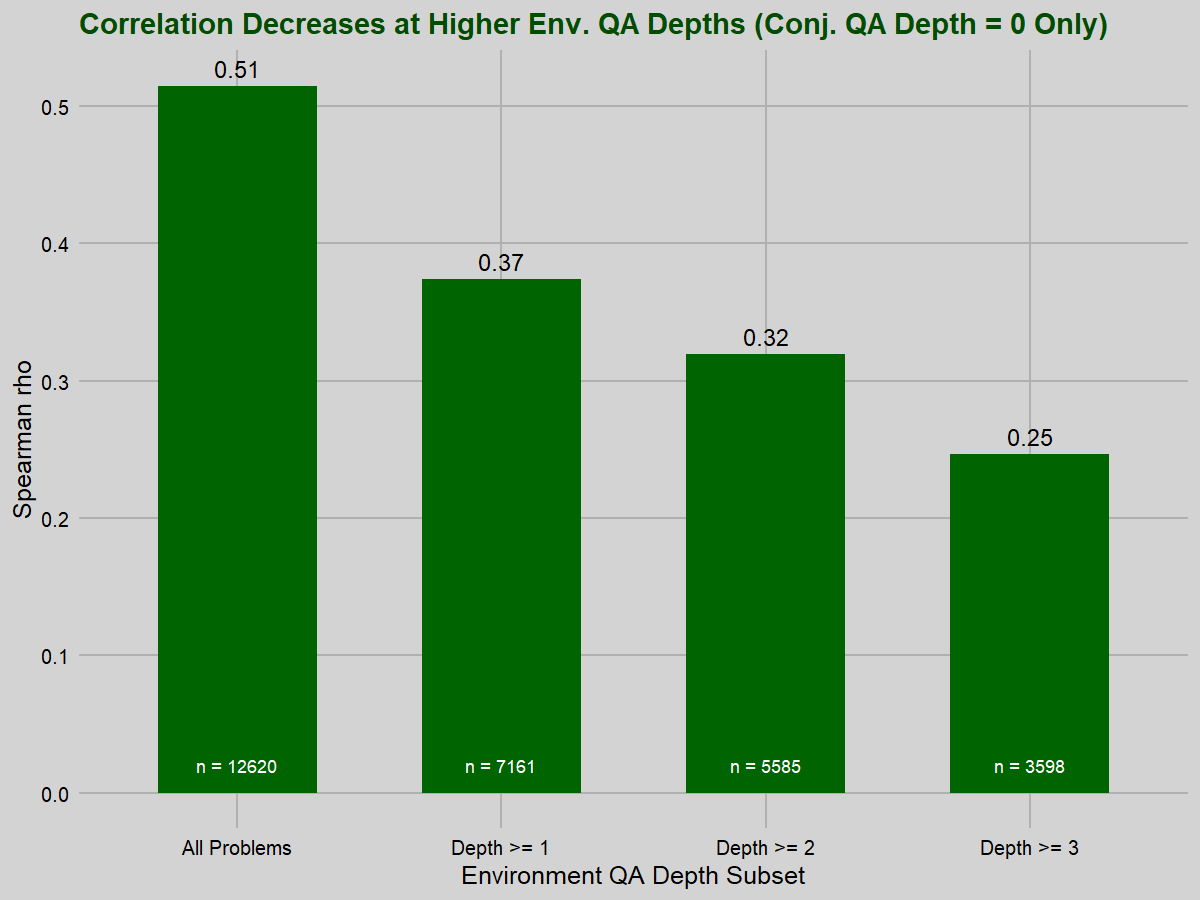
When we hold conjecture QA depth fixed at 0, we still see a strong correlation between environment QA depth and difficulty rating (rho=0.515, p<0.001), actually stronger than the overall correlation noted above. We can visually see the mean rating increase with environment QA depth:
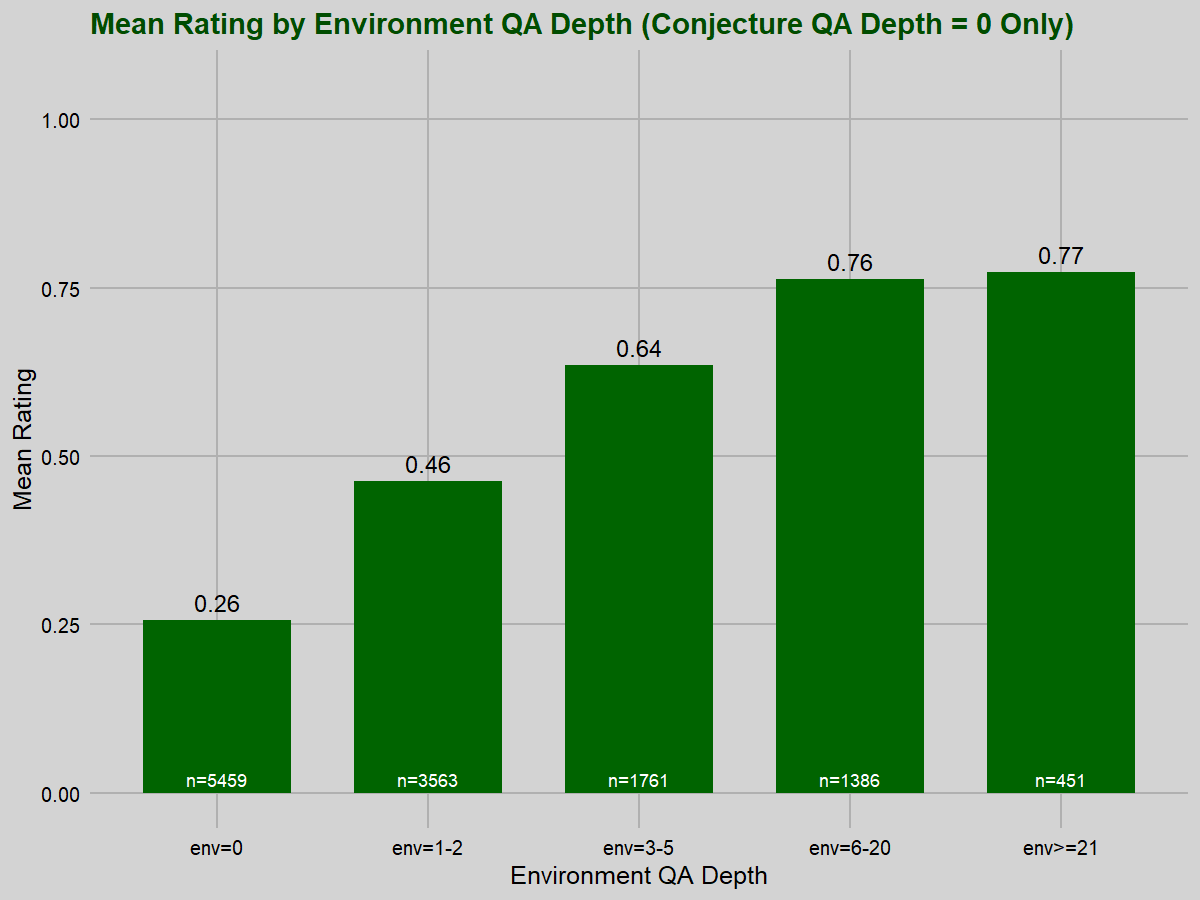
As before, this correlation noticeably decreases when we remove environment QA depth 0 problems (rho=0.374, p<0.001). After that, it erodes steadily as we remove problems of greater depth levels.
Total quantifier count versus difficulty
We can also compute total existential and universal quantifiers from the problem statistics file, summing the “!” and the “?” columns, and see to what extent raw quantifier count impacts problem difficulty. The results are striking: total quantifier count is a (slightly) stronger predictor of difficulty (rho=0.511, p<0.001) than is alternation depth.
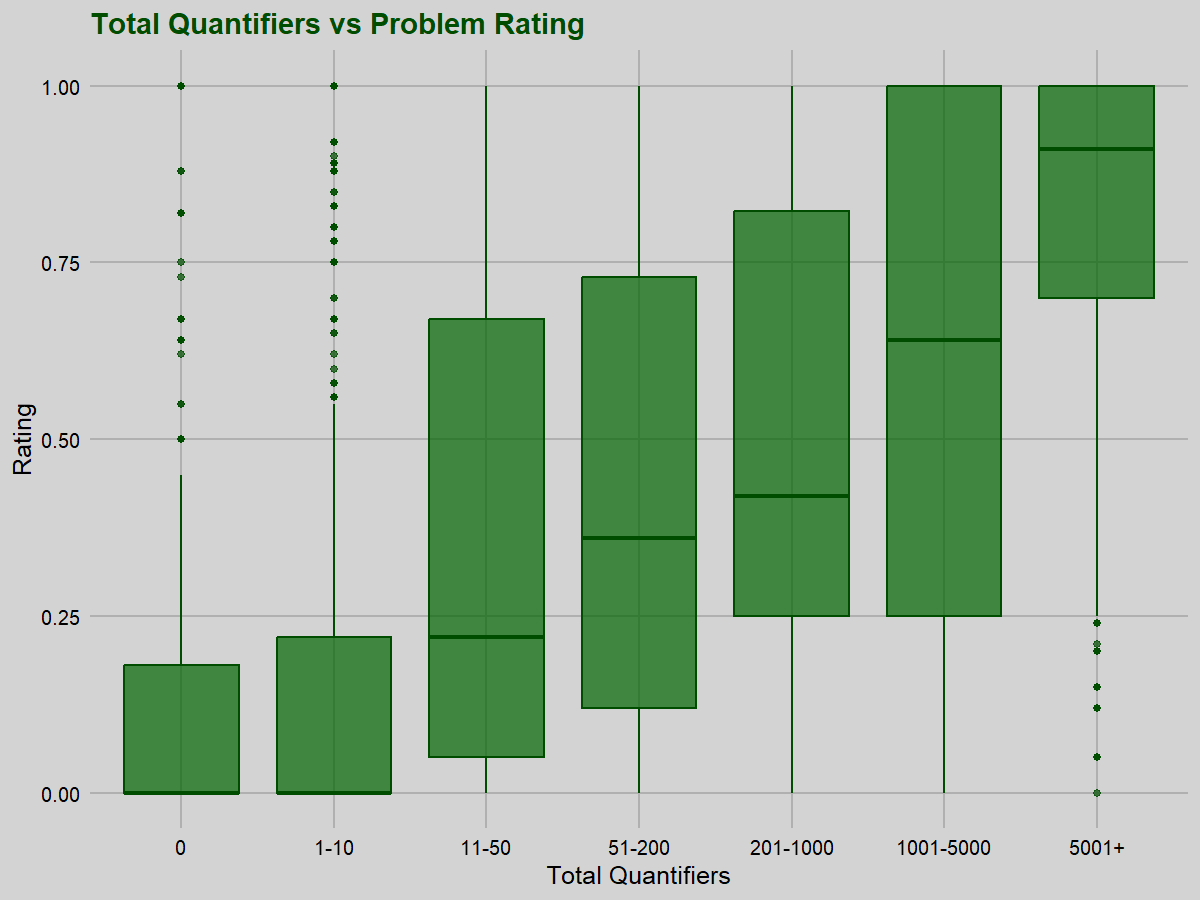
We do not see any evidence of a diminishing returns effect here. Removing problems with zero total quantifiers (rho=0.487) or those with zero or one quantifiers (rho=0.466) has very little effect (both p<0.001). Adding the TF1 and TX0 problems also makes very little difference, nor does removing problems that have total quantifier counts in the top 1% of values.
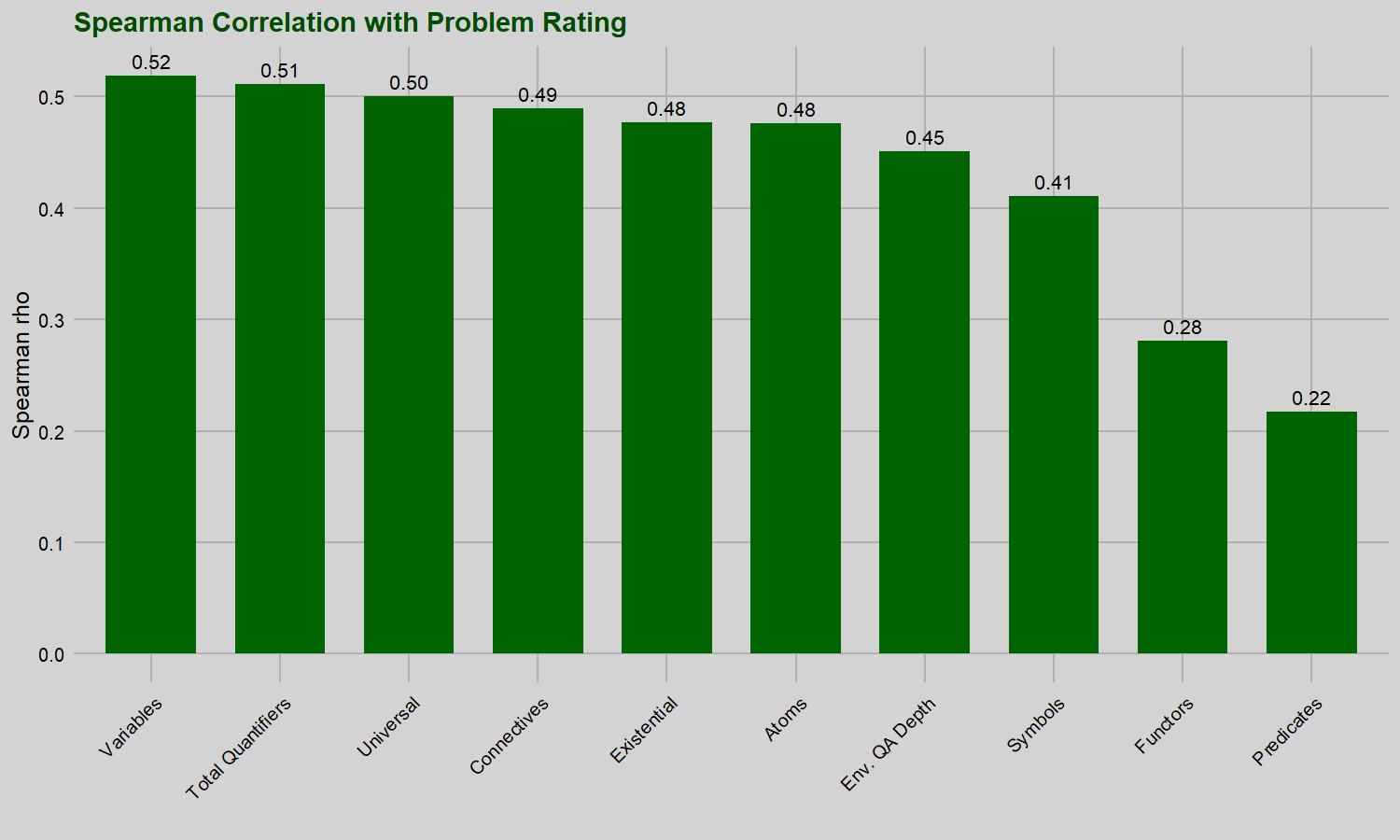
Other variables versus difficulty
Overall, many other problem variables follow a similar pattern to total quantifier counts and are just as much or slightly more correlated with problem difficulty than environment quantifier alternation depth. This suggests that the apparent link between quantifier count and problem difficulty is less likely to be driven by something special about quantifiers themselves and more likely to be due to the fact that we are dealing with ever larger problems.
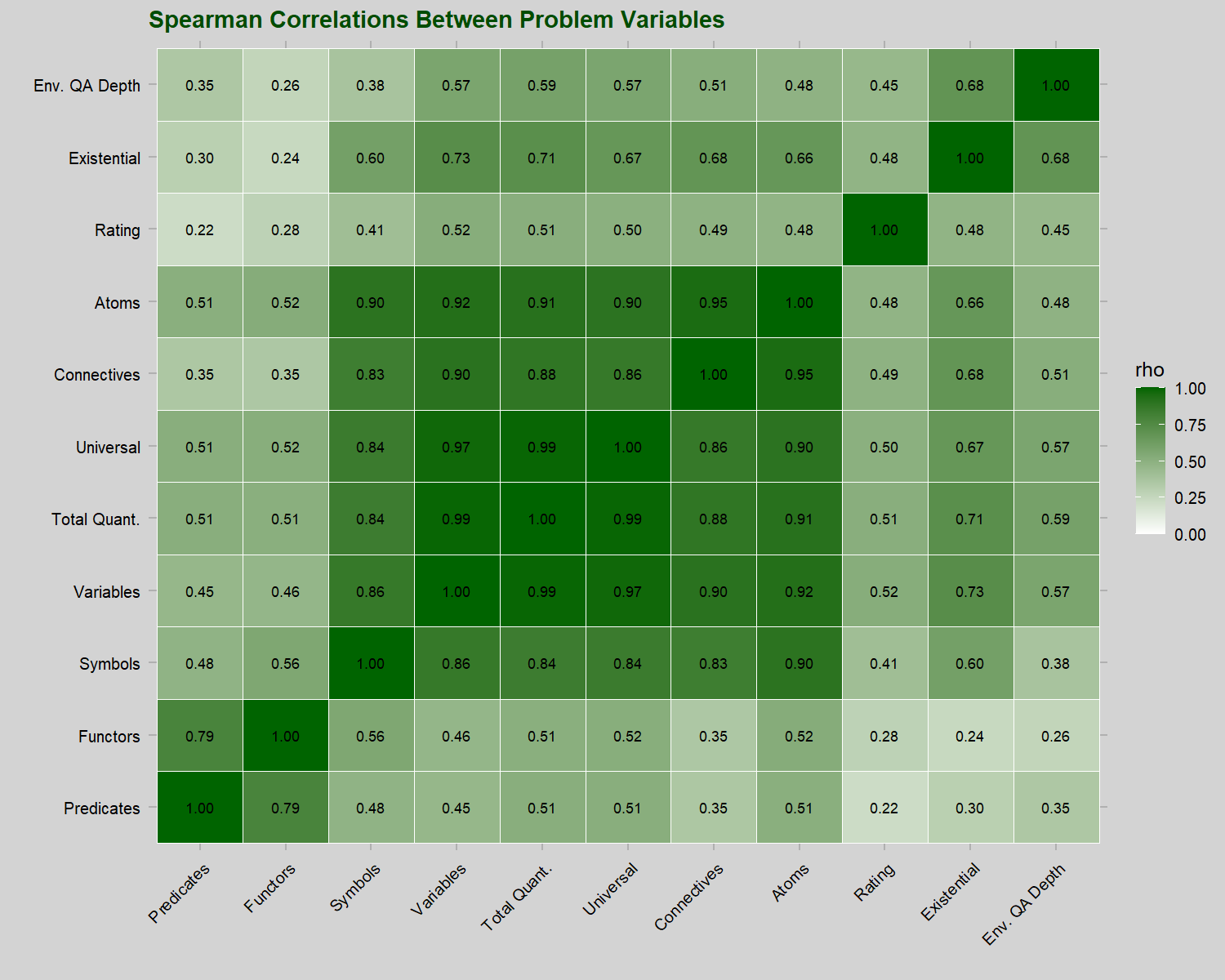
These other variables are mostly similarly correlated with one another, as expected given that these should mostly scale together as problems get longer.
Conclusions
-
The number of quantifier alternations in the problem statement by itself has zero correlation with problem difficulty rating.
-
There is a notable difference in difficulty between statements with no environment quantifier alternation versus those that have some. This holds even when we remove the contribution from the conjecture statement itself.
-
Problems with more quantifiers in general tend to be harder for automated solvers. However, it appears that this has less to do with something special about quantifiers and more to do with having to handle problems that have more of everything, because we see the same correlation between other variables that increase the problem statement length and problem difficulty. Total quantifier count is highly inter-correlated with many of these other variables that reflect total problem size – to a much greater extent than environment QA depth.
Parting thoughts
Timothy Gowers has a blog post, “What is deep mathematics?”, in which he suggests that the difficulty or depth of a problem can often be linked to it requiring the construction of a mathematical object because the choice of which object to create is often non-unique and non-obvious and therefore hard to algorithmically codify.
Terence Tao left a comment on that post that suggests that another measure of difficulty could be the extent to which the statement to be proved uses properties of the underlying structures it is about (such as one statement requiring significantly more properties of the real line than another).
One existing set of methods that formalizes such a notion is the field of reverse mathematics, which can be used to compare various theorems by looking at the axiom systems required to prove them. A theorem A can be said to be deeper than a theorem B if a set of axioms can be found that proves B but not A. Nevertheless, according to John Stillwell (2018), these techniques remain limited:
“…we must admit that reverse mathematics has so far revealed signs of “depth” only in theorems about infinite objects, such as real numbers or subsets of $\mathbb{N}$. There has been little progress on theorems about the natural numbers. The only examples where we might say Theorem A is “deeper than” Theorem B is where Theorem B is provable in PA [Peano Arithmetic] and Theorem A is not. Few such examples are known…”
References
- Jerome H. Keisler, Quantifiers in Limits. In: Andrzej Mostowski and Foundational Studies, IOS Press, Amsterdam, 2008, p. 151-170.
- Geoff Sutcliffe, The TPTP Problem Library and Associated Infrastructure. From CNF to TH0, TPTP v6.4.0, Journal of Automated Reasoning 59:4 (2017), p. 483-502.
- Geoff Sutcliffe, Christian Suttner, Evaluating general purpose automated theorem proving systems, Artificial Intelligence 131 (2001), p. 39-54.
- John Stillwell, Reverse Mathematics: Proofs From the Inside Out, Princeton University Press, Princeton (2018).
- Math Overflow thread 281894, “Examples of statements with a high quantifier complexity”.
- Martin Davis, Yuri Matijasevic [Matiyasevich], Julia Robinson, Hilbert’s Tenth Problem. Diophantine Equations: Positive Aspects of a Negative Solution. In: Mathematical Developments Arising From Hilbert Problems, Part 2, Proceedings of Symposia in Pure Mathematics, Vol. 28, American Mathematical Society, Providence, 1976. This chapter shows how many famous problems can be stated in the form $(\forall n)P(n)$ with a decidable $P.$